Prepare your data¶
Once you have imported some data from your datasources in Toucan Toco, you may need to add some cleaning aggregations, tranformations, computations or to combine several datasets together.
Instead of repeating those operations in every query of your stories, you can prepare and load new datasets ready to be consumed in your stories. It will help you gain both efficiency and performance, by avoiding repetitive and resource-consuming operations that you would otherwise perform on-the-fly in each and every query of your stories.
Let’s see how this work.
Note
Toucan Toco offers data preparation capabilities meant for analytics purposes. Our ambition is to simplify data preparation when it comes to creating a dashboard to make everyday business decisions, while other tools, outside of the BI market, are specialized in complex and heavy data preparation. As a consequence we are offering a guided experience for data preparation designed for those regular business use cases, using data often already aggregated and cleaned up, with a standard amount of data (millions of rows).
Create a new prepared dataset¶
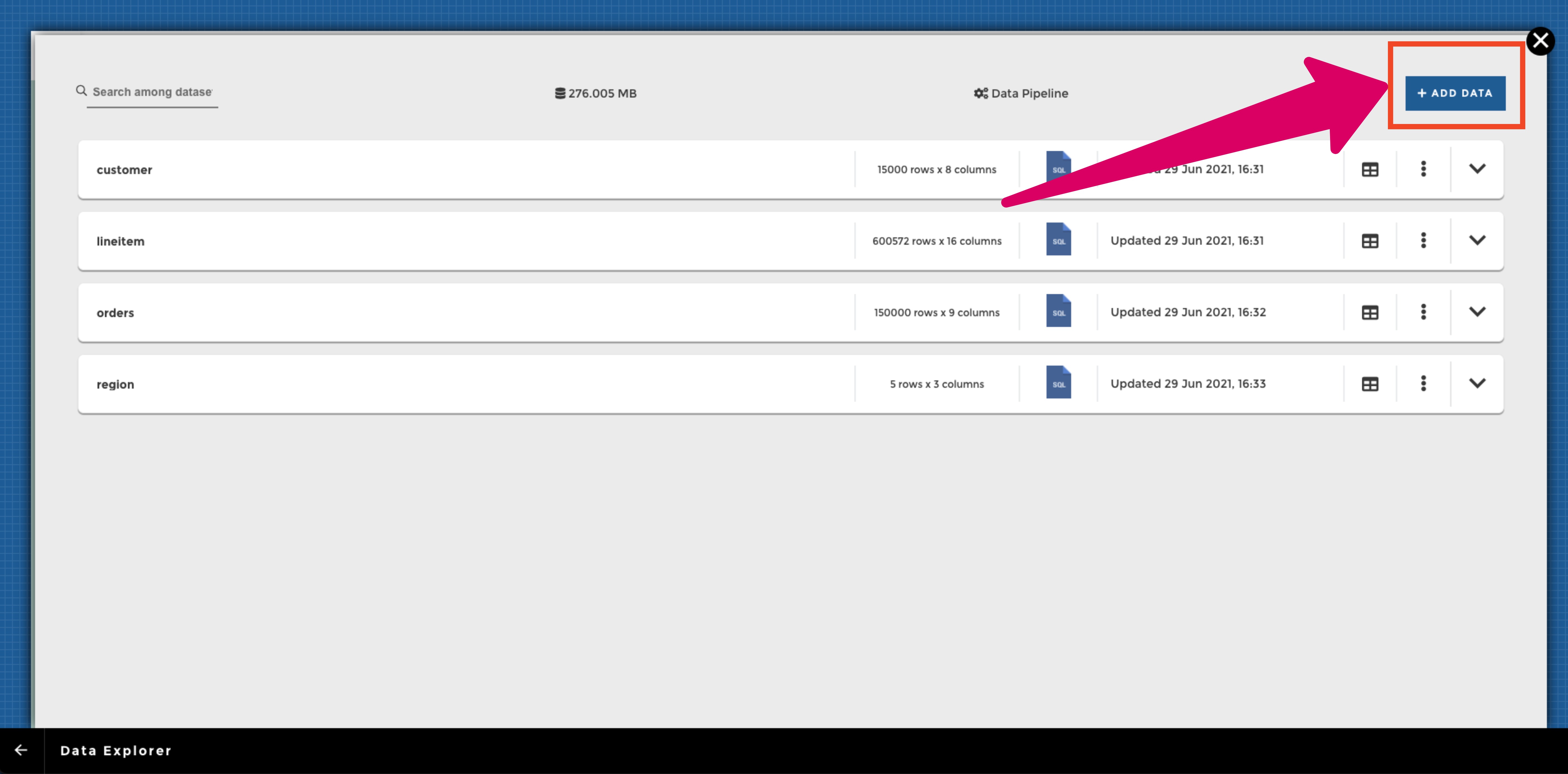
To create a new prepared dataset, go to your Data Explorer (in the “DATASTORE” tab of your Studio toolbar):

Then click on the “ADD DATA” button in the upper right corner of your data explorer, and select “From existing data”:
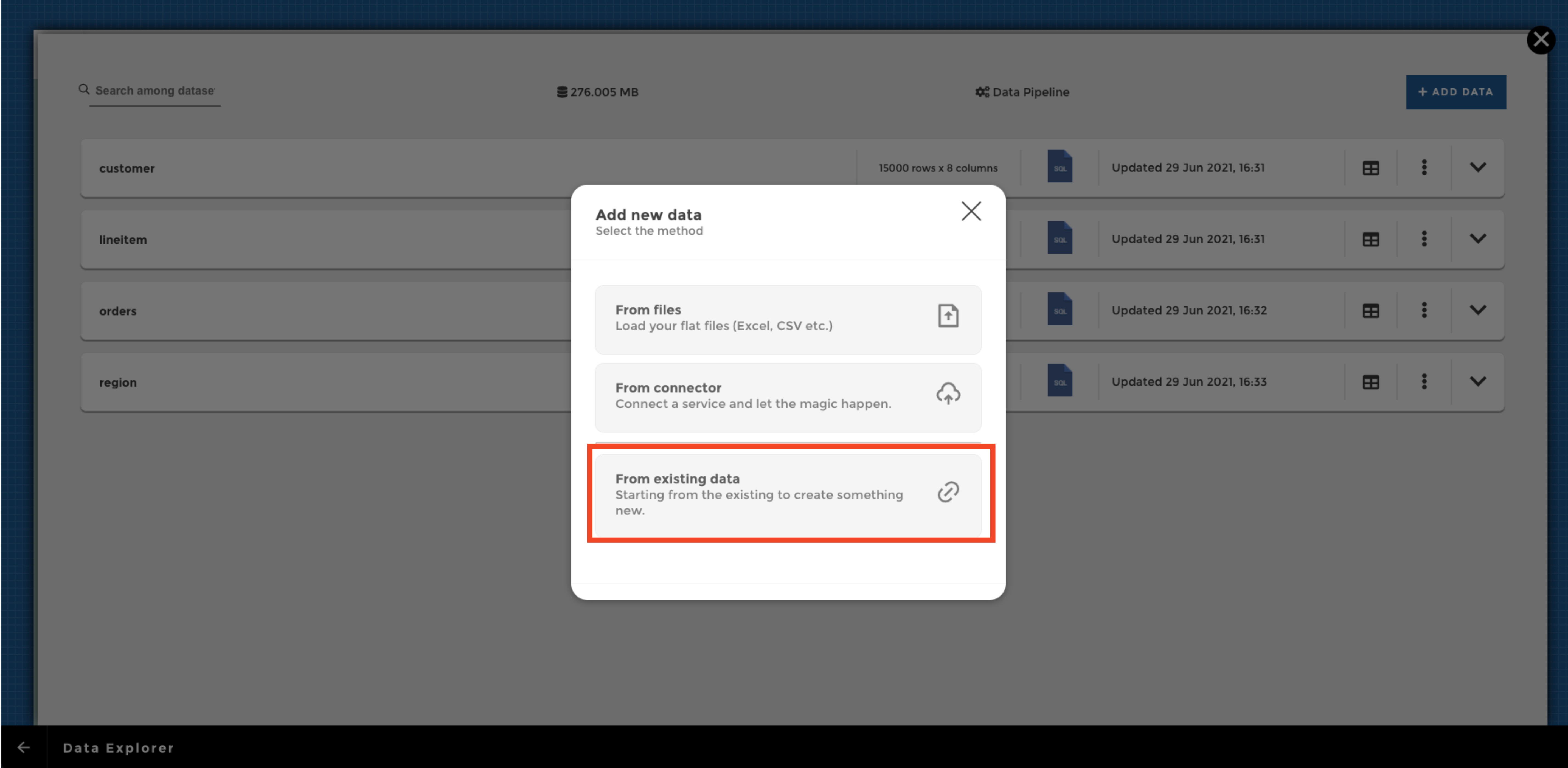
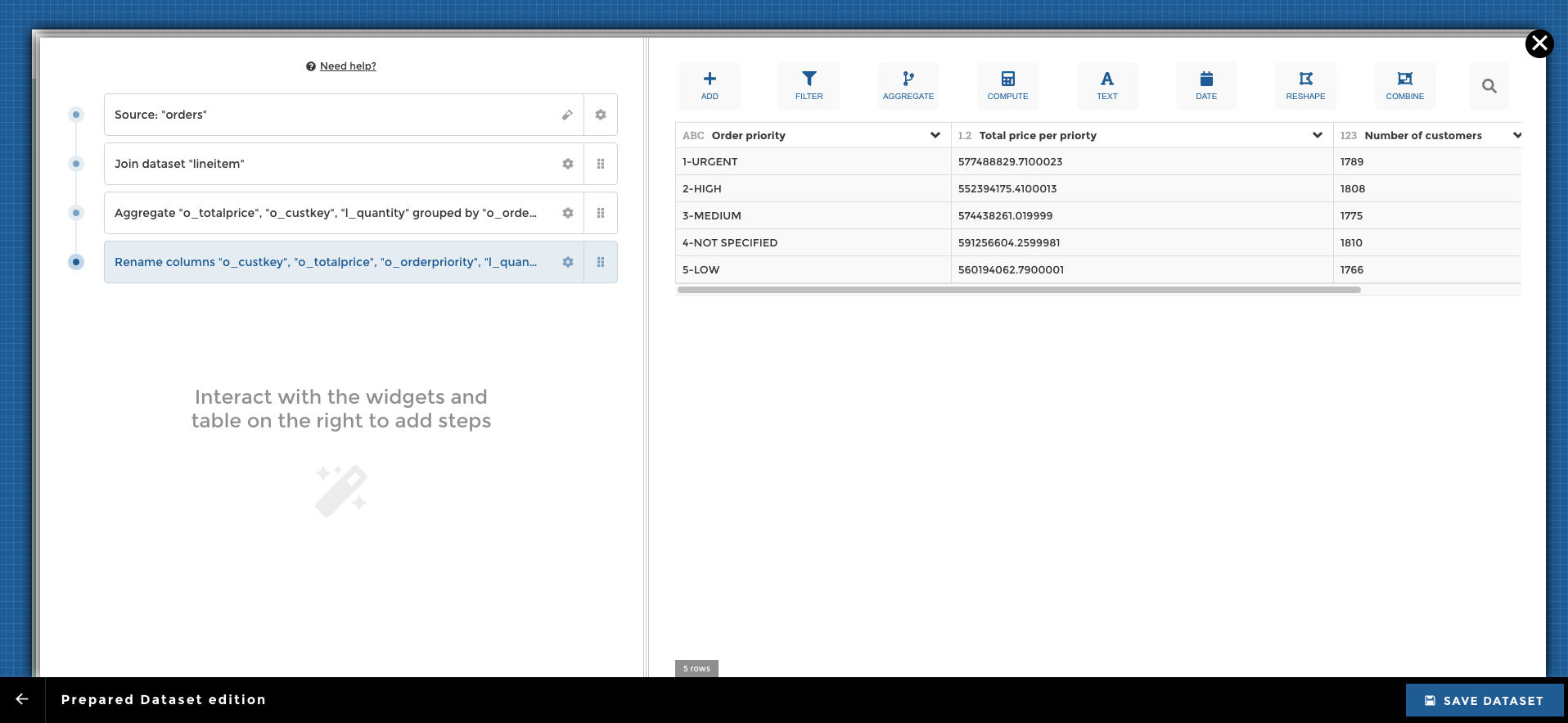
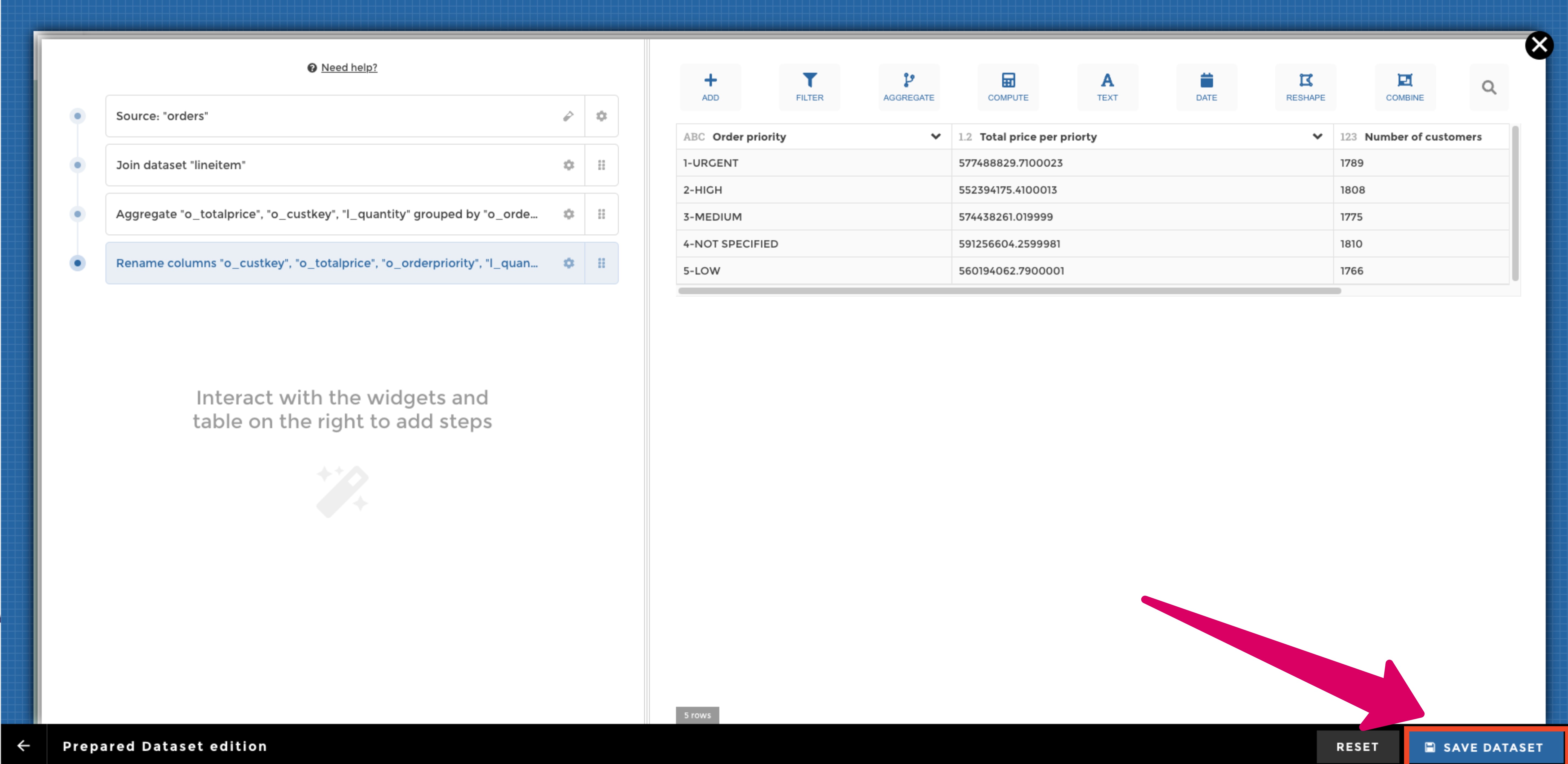
Then you need to pick an existing dataset to start from. Once it’s done, you can apply your transformations using our visual query building module YouPrep™ (in the example below we combine the order datasets with the line item dataset, and then group by the order priority and finally rename columns):
Note
In order to avoid waiting times between each step, we have limited computation of each step to the 10 000 first rows of the dataset in the preview.
As a result the preview on the right might show an inaccurate result. Don’t worry!
- When you will save your prepared dataset the computation will be made on the whole dataset
- We have given you the option to change this default limit: either lower it to have even faster preview or increase it to have accurate results
To do, so click on the sample icon on the first step

Type the number of rows you want to have your preview computed on and click on the refresh button. The preview will then be recomputed using the number of rows of your datasets as an input.

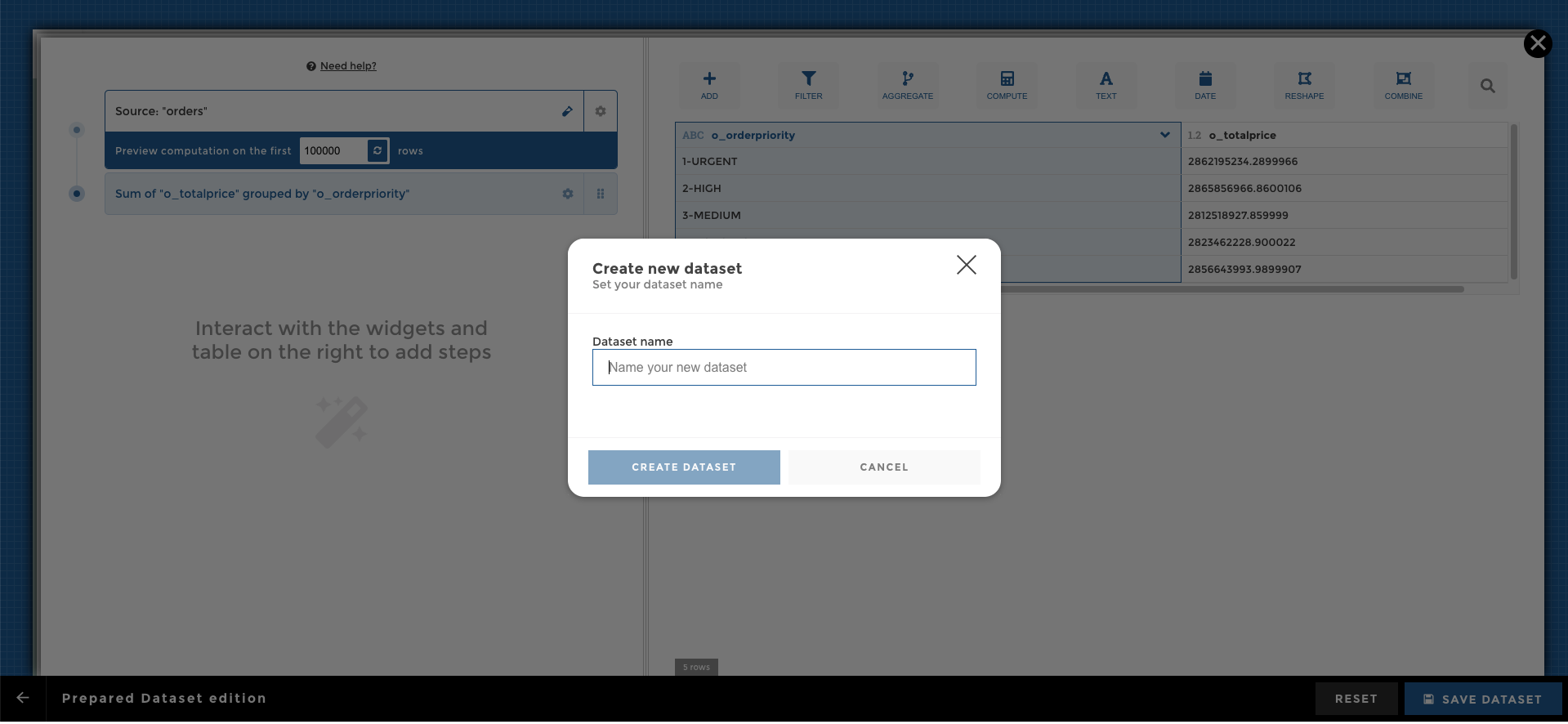
Once you are fine with your cooking, you can save your new dataset via the button in the bottom right corner, and you will then be asked to give a name to your dataset:
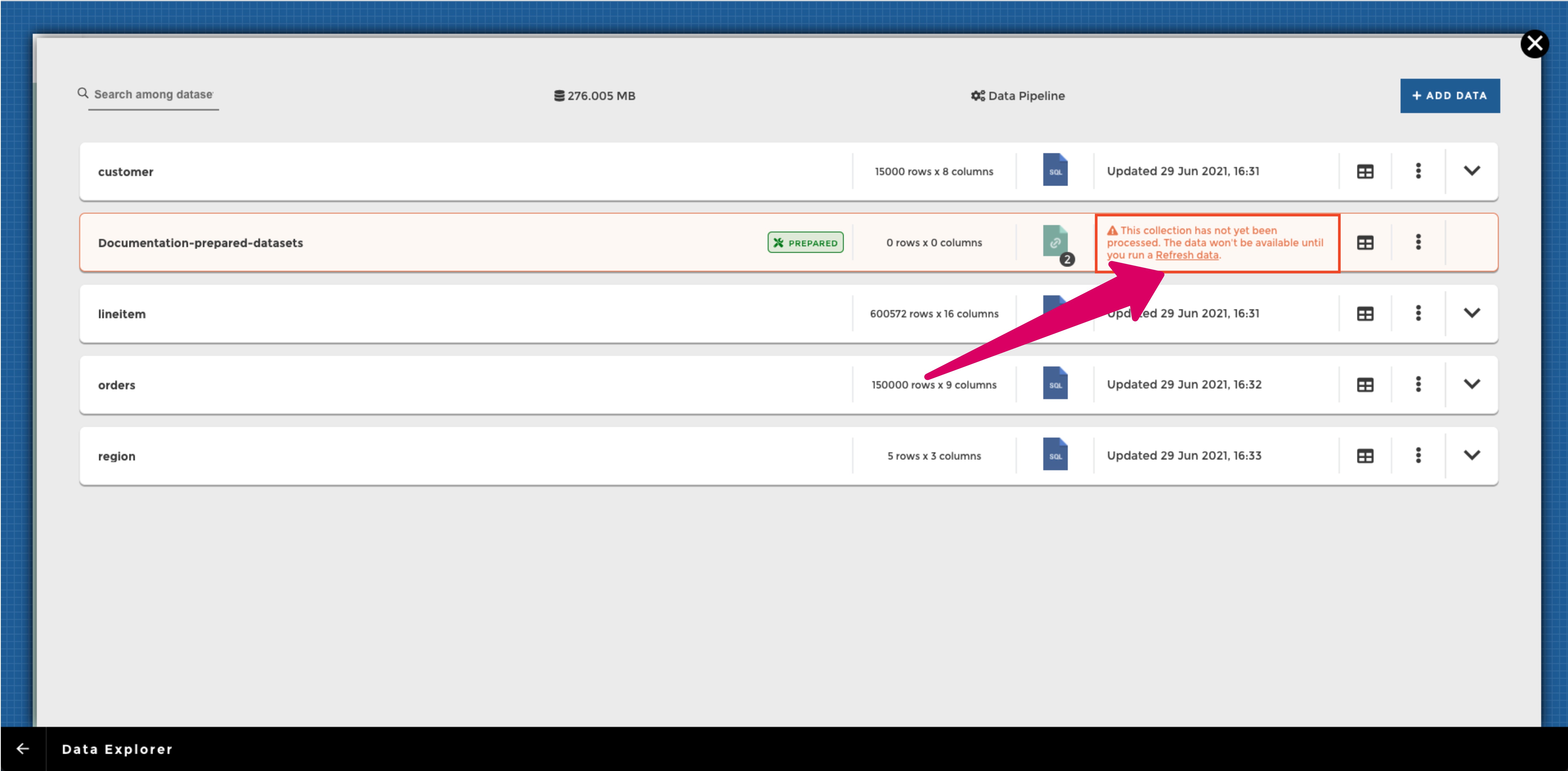
The Prepared dataset will then appear in your Data explorer tab, click on “Refresh data” to have the computation run on the whole dataset and get done.
Load / refresh a prepared dataset¶
When you have just created a new prepared dataset, when you get back to your data explorer you will see that your new dataset appears in orange with a message indicating you that it needs to be processed before it can be loaded and used in your stories:
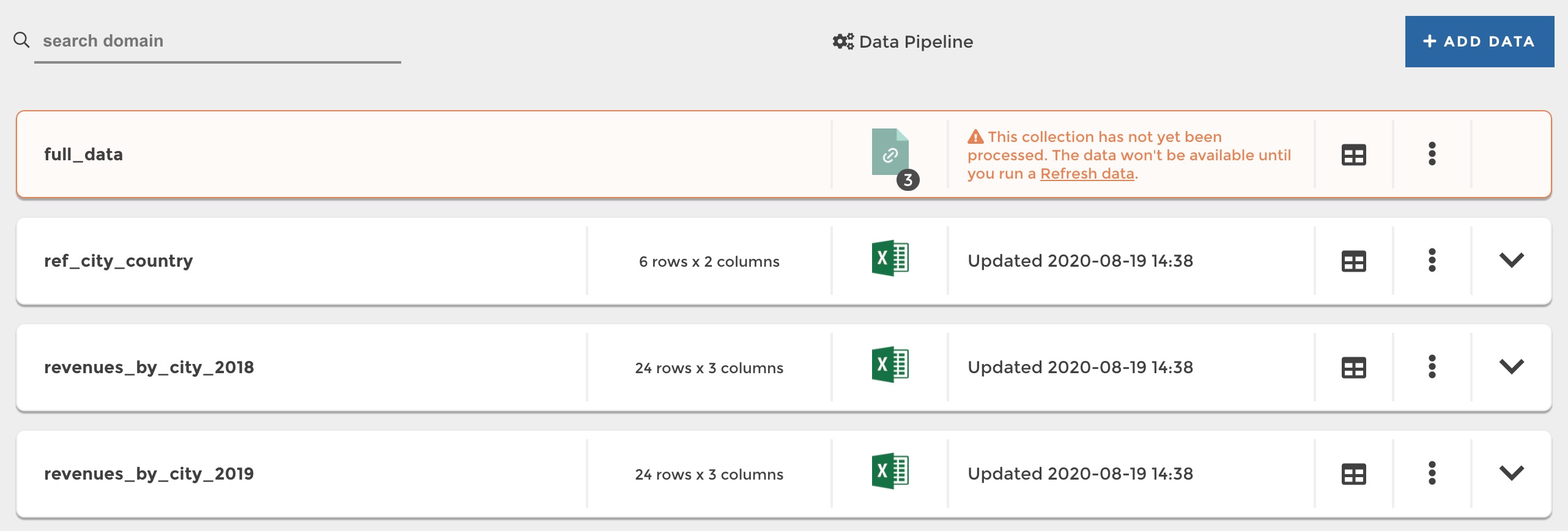
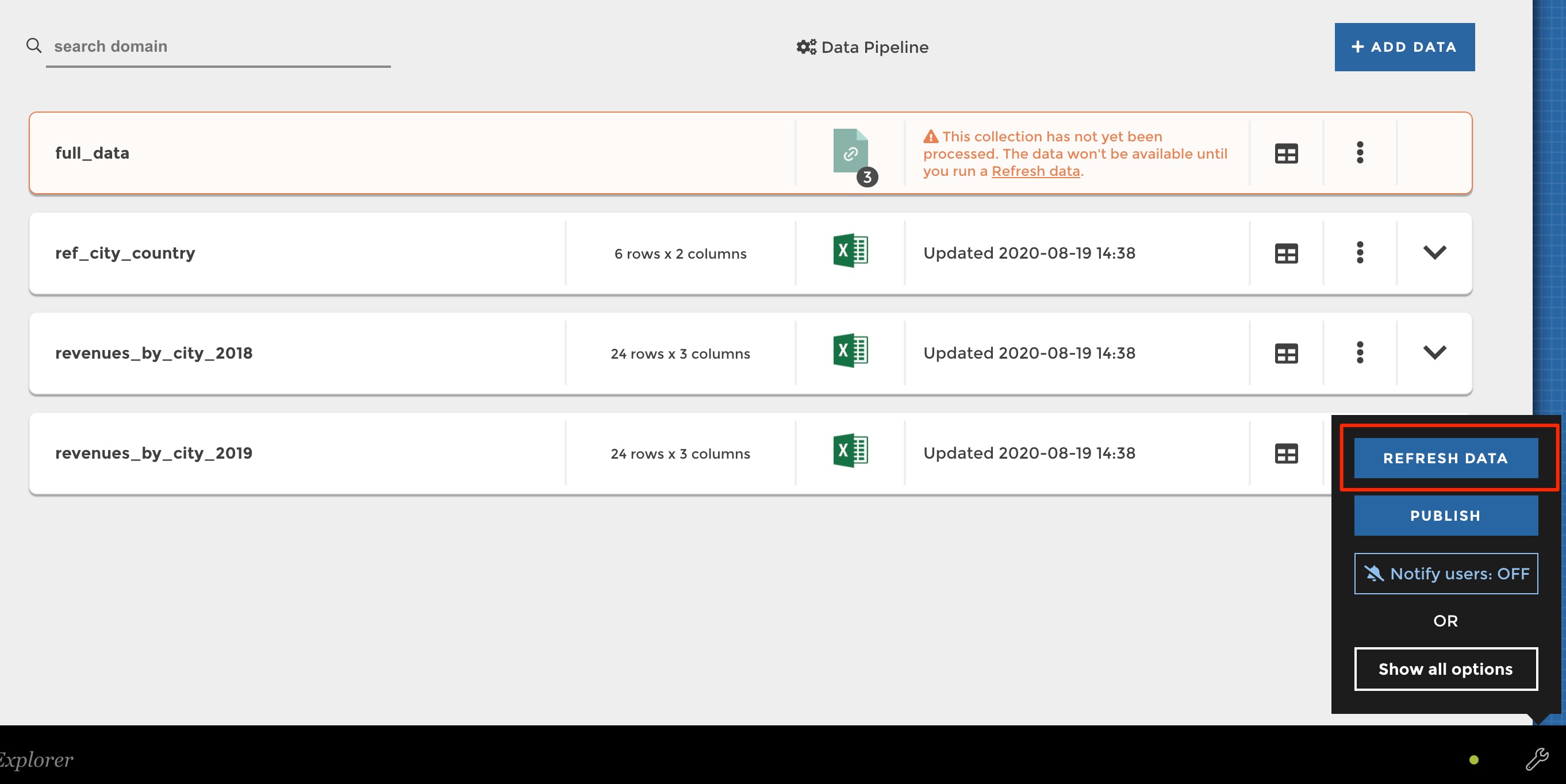
To process your dataset, you have 2 options:
- Process only your dataset. This is the preferred option if it’s the only dataset that you need to refresh. When you do so, this dataset as well as all the others that depend on it or that it depends on will be refreshed.
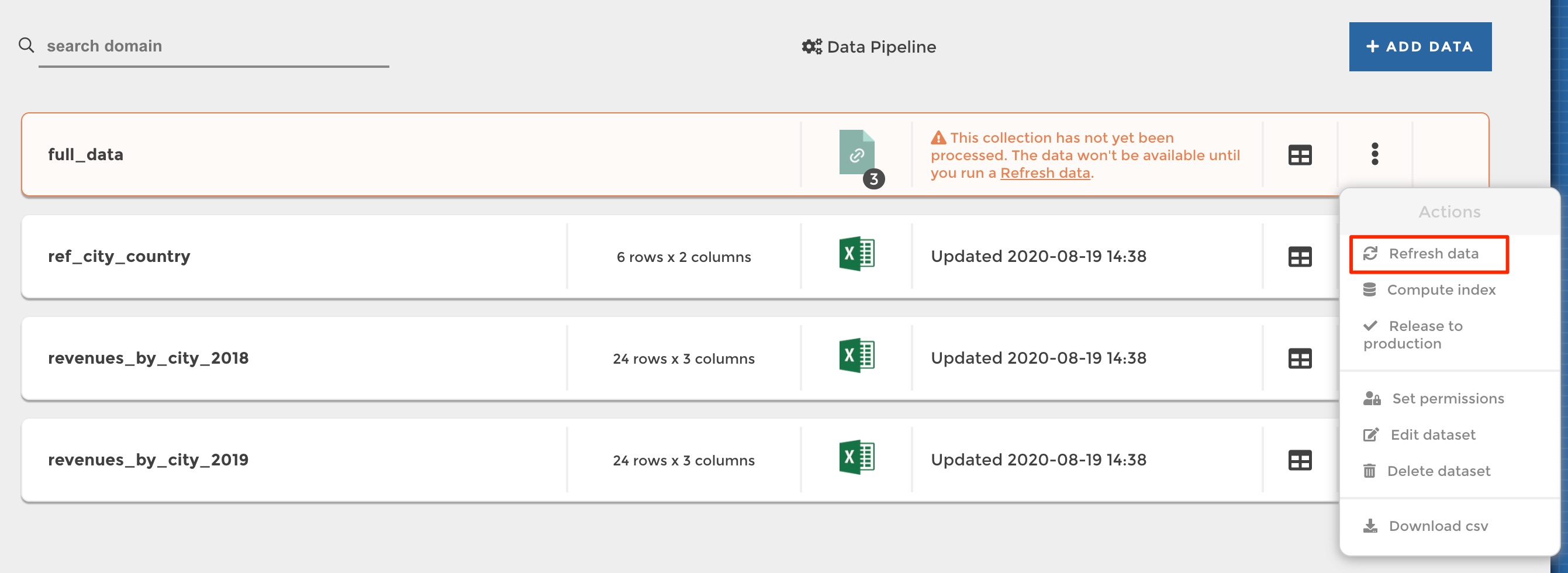
- Process all your datasets
Edit or delete a prepared dataset¶
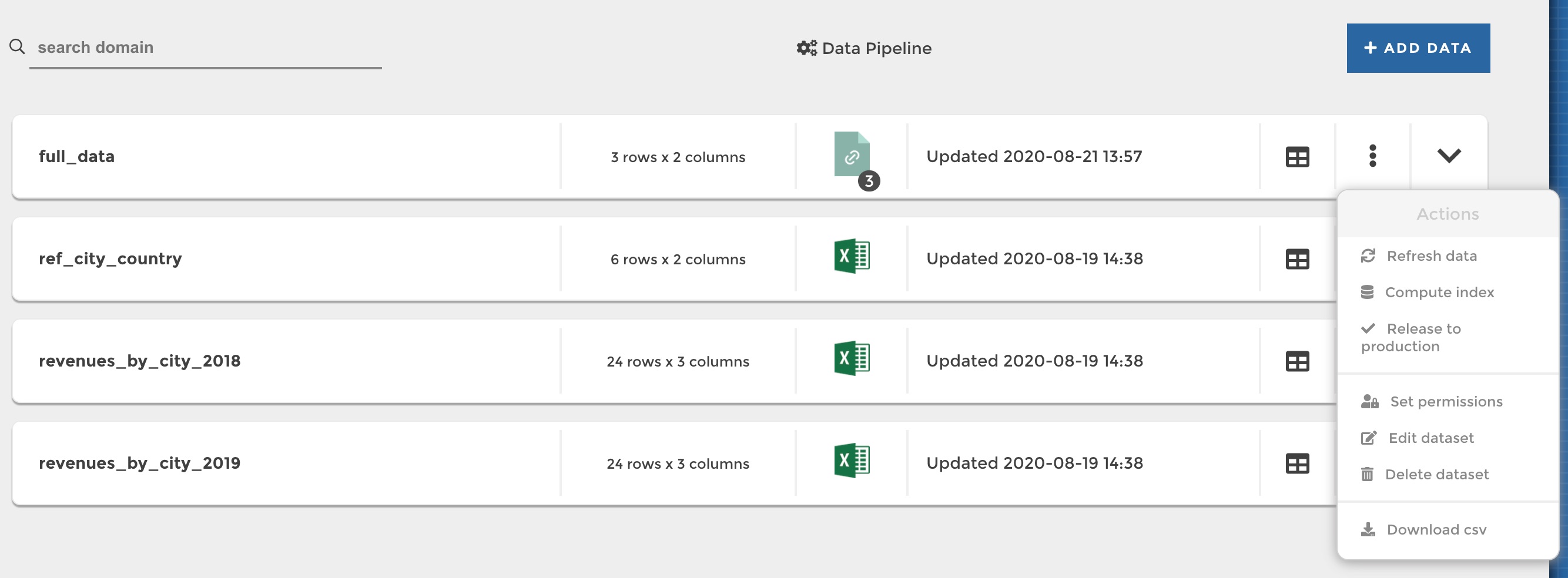
Of course, you can easily edit a prepared dataset and update your data transformations, or delete it:
Dependencies between prepared datasets¶
Several rules to keep in mind in terms of dependencies between prepared datasets:
- When you refresh a dataset, it launches the process of parent datasets and dependant datasets
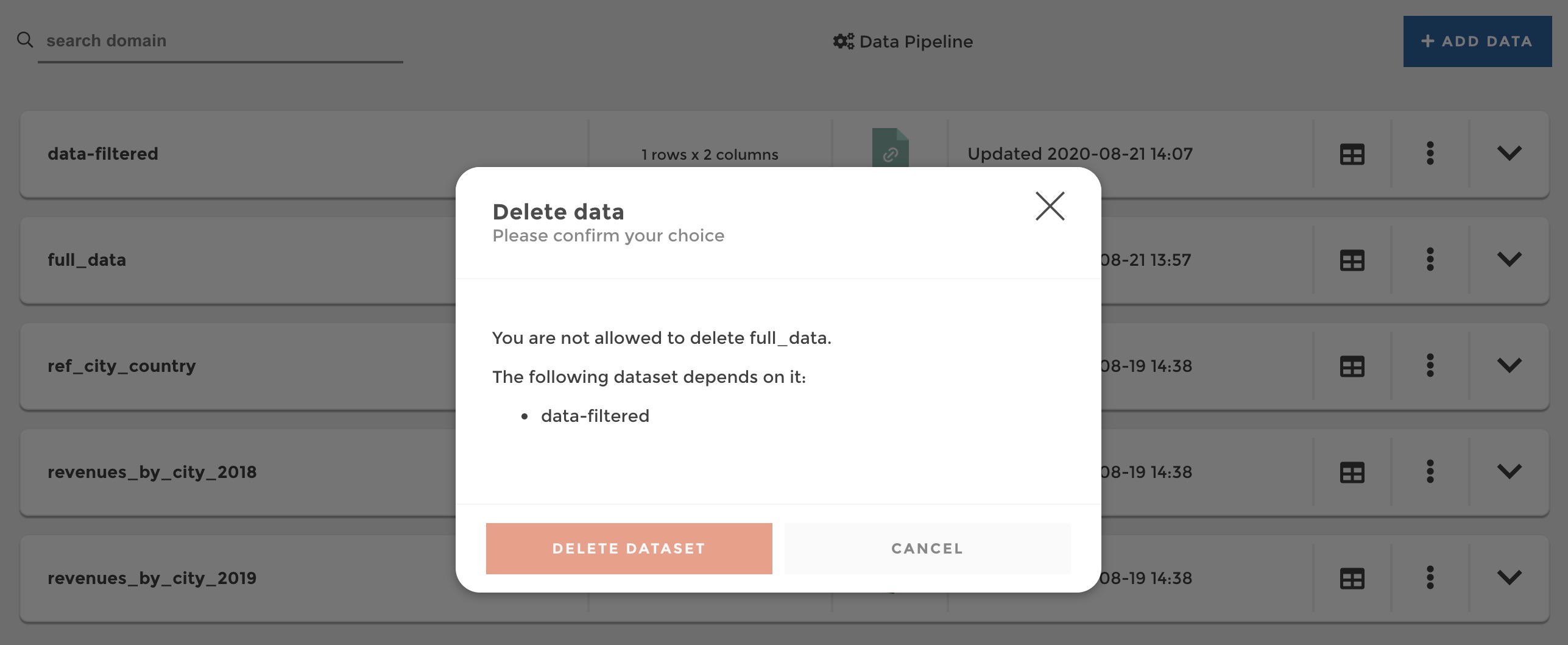
- You will not be able to delete a dataset if it is referenced in another dataset.
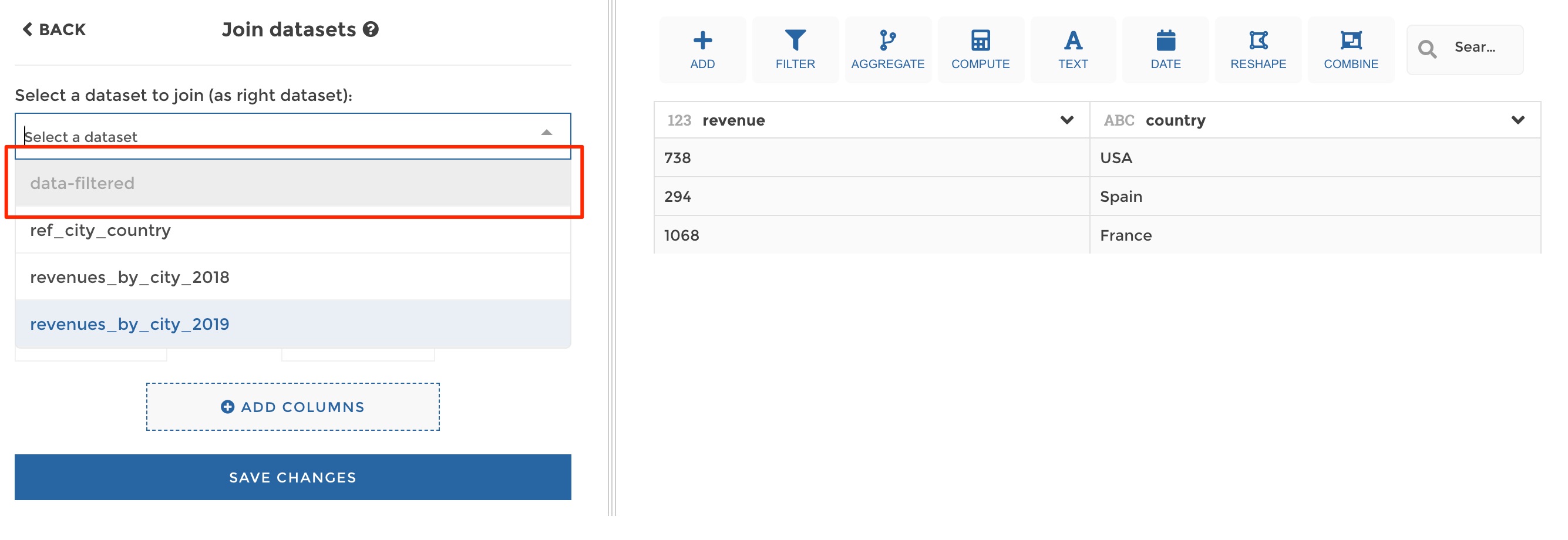
- You will not be able to append or join another dataset to your current dataset when it would create circular reference. Such a forbidden dataset will appear deactivated, in grey, in the dataset selection dropdown of the append/join step: